2021 saw the completion of my first substantial free software project: a TLA⁺ grammar for tree-sitter, the error-tolerant incremental parser generator. The project stabilized & found users over the course of 2022, then over the holidays I used it to build the TLA⁺ Unicode Converter. The new year is a time to reflect on the past and look to the future, so here in early 2023 seems ideal to publish my experience.
Both TLA⁺ and tree-sitter itself ensured the project was fascinating on a technical level; even more interesting were the social and psychological aspects of my first real involvement with the free software community! I’ll go over why I wanted to create this project and the main technical challenges I faced doing so, then discuss the conditions that enabled me to create it and how free software development changed the way I think. If you’d rather get the technical part in video form (with demos!), you can watch the presentation I gave at TLA⁺ Conf 2021 (slides: pdf, odp):
You can find the grammar here or take it for a spin in your browser.
Why write this parser?
I love TLA⁺. The language is just fantastic; it has enabled me to design, reason about, and implement so many systems that would otherwise be riddled with concurrency bugs. However, it isn’t really a secret that the user experience is a bit clunky; like many tools with roots in research & academia, it has been slow to move on from monolithic custom GUI-based IDEs. Although the TLA⁺ Toolbox works quite well in my opinion, these days people like well-designed CLIs with git-friendly source & config files, CI/CD-friendly tools, and lightweight zero-config language support in their personalized editor. There has been some progress here with the TLA⁺ VS Code extension, but I think a big stumbling block is that SANY, the sole feature-complete TLA⁺ parser, is somewhat inscrutable for language tooling purposes. Accessing and querying the parse tree is not straightforward. I wanted to create a TLA⁺ parser where this functionality was front & centre, with a focus on language tooling developer experience instead of end user experience. I also wanted to finally bring really great syntax highlighting to TLA⁺. Conventional syntax highlighting uses regular expressions to half-assedly parse non-regular languages. Although it requires more work up front, a syntax highlighting system using context-free (or even context-sensitive!) grammars to parse languages in the same level of the Chomsky hierarchy makes lot more sense. Enter tree-sitter!

{kind=link}
Language servers vs. tree-sitter
First, a digression: if you’ve hung around any developer news or discussion forums over the past few years you’ve probably heard about tree-sitter. Unfortunately the subsequent discussion probably immediately went off on a tangent talking about language servers, so I’ll take some time here to describe the similarities & differences and hopefully move the discussion forward. Basically, tree-sitter is a software project that helps you write parsers for programming languages. People these days rarely write parsers by hand unless they really want to get into the weeds and create an industrial-strength implementation with full control over behavior, optimization, and error reporting; much more common is the use of a parser generator, where you use a nice DSL resembling a formal grammar and the generator emits the necessary gnarly string processing code in C or some other language. There are a lot of parser generators out there, so what’s so special about parsers generated by tree-sitter? Four things:
- They’re error-tolerant, so they can parse files even if the user is halfway through writing a block of code
- They have incremental parsing, so they can very quickly re-parse only the code that has been edited by the user
- They have a standardized query API, so you can quickly find syntax occurrences
- They have minimal uniform runtime requirements, so programs can consume many different tree-sitter grammars without much overhead or customization
These properties make them ideal for language tooling. I wouldn’t use a tree-sitter grammar as the backbone of an interpreter, but they’re great for cases where an approximately-correct parse works fine, like:
- Syntax highlighting or semantic highlighting
- Symbol/reference finding (GitHub is using tree-sitter with stack graphs for this)
- Code analysis, linting, or transformation tools
- Coding with alternative input methods for accessibility (cursorless uses tree-sitter)
- Code folding
All of these can be implemented with little more than clever use of tree-sitter’s standardized query API, customizing the tool’s functionality for each supported language with a file that maps query captures to known names. For example, these files are all that were necessary to get TLA⁺ highlighting and code folding working in Neovim.
Contrast this with language servers. The Language Server Protocol (LSP) was created to address the problem of needing to write a separate extension for each programming language and each editor; by implementing a standard capabilities-based API, you can write a single language server for your programming language and have it be supported out of the box on a wide variety of editors, thus turning an \(N \times M\) problem into an \(N\) problem:

The API includes generic high-level requests like “go to symbol definition” or “find all symbol references”. Each language server has nonstandard runtime requirements and is written in whatever programming language the creator desires; often times it’s written in the same language it’s serving (the language server for R is written in R!). You could even use tree-sitter inside your language server implementation, as was done with the bash language server. Fundamentally language servers are much higher-level, heavyweight, unique beasts than tree-sitter grammars. They are the ultimate form of language tooling, while tree-sitter grammars are themselves used to build language tools.
Language servers and tree-sitter grammars are wildly different; however, the small amount of conceptual overlap and the tendency for their support to be announced as side-by-side headline features ensures confusion will reign for quite some time.
Writing a tree-sitter grammar
I’d never written a parser before. One of my great undergrad CS regrets is never making it through the compilers course. Still, I’d done pretty well in the formal languages class so that was something; the basic Extended Backus-Naur form (EBNF) is intuitive enough. But how can you translate language syntax to EBNF? I’ll tell you how you shouldn’t do it: by writing the language in EBNF as you know it from experience, then fleshing it out by guessing & checking whether the gold-standard parser accepts some syntax. Put in the legwork and look for the docs! Nearly all languages will have some kind of old language spec document floating around. Depending on how forward-thinking the language designer was, this might even itself contain a detailed EBNF grammar! Possibly the language spec is old and out-of-date, but it’s much, much better as a starting point than your own experience using some subset of the language syntax. Thankfully TLA⁺ has such a document, and as you might have expected for a formal specification language the grammar spec is written in TLA⁺ itself! This got me about 50% of the way there.
Unfortunately implementation slowly diverged from specification, as often happens. TLA⁺ really only has one widely-used parser called SANY (the TLA⁺ Proof System has its own parser written in OCaml but this is not used anywhere else). SANY was written in Java around a decade ago, using the JavaCC parser generator. JavaCC grammars are written in a sort of EBNF, and SANY’s EBNF grammar diverges from the supposed TLA⁺ standard. Unfortunately that isn’t the end of it, because the code generated by JavaCC was subsequently hand-edited: the implementation diverges from the specification diverging from the specification! My task thus became synthesizing these fractured accounts of what TLA⁺ is into a coherent whole, then hopefully backporting this understanding to the original language spec so nobody else would have to go through what I went through. This was by far the most tedious part of the entire project. The days stretched into weeks and at times I couldn’t see the way through - would I really manage to climb out of the quagmire? Finally, after painstakingly chasing down every correspondence of parse tree node to grammar rule I claimed victory and filed a PR against the original language grammar with all the changes. May nobody ever again suffer in this way. At this point I thought I was about 90% done.
The other 90%
In software engineering people often talk of finishing the first 90% of a project, then having to work on the second 90%. So it was with this grammar. After wrapping up the EBNF work I had finished all the context-free parts of the language. TLA⁺ isn’t a context-free language, though. It has context-sensitive parts. These terms have precise formal definitions, but basically you can think of context-sensitive language constructs as changing their meaning depending on surrounding language constructs. In order to properly parse them you have to keep track of what you’ve seen before that point. A simple example is python’s use of indentation level to mark code blocks: the meaning of a given line of code depends on its columnar position and the columnar positions of previous lines of code. As you parse the code you have to carry some extra state along with you, a stack of nested code block indentation levels (actually this might move beyond context-sensitive and require full Turing completeness because to write this in EBNF you’d need to parameterize grammar rules with their indentation level, but I’ll leave this one up to the formal language theorists). TLA⁺ uses indentation levels similarly when writing conjunction & disjunction lists:
op == /\ A
/\ B
/\ \/ C
\/ D
/\ E
Here the conjunct and disjunct bullet alignments ensure this expression is interpreted as (A ∧ B ∧ (C ∨ D) ∧ E).
This is a very handy way to write long conjunctions & disjunctions, one of the big language features of TLA⁺, so I had to handle it properly.
The way to write context-sensitive language rules in tree-sitter is to use an external scanner: a hand-written C or C++ file encoding your own custom lexing logic.
Many years ago I’d sworn to myself I would never again write C or C++.
Sadly I now found I had to break that oath; tree-sitter generates a gigantic parser.c file, and (currently) the only supported method of writing an external scanner is to write an accompanying scanner.cc file that parser.c calls into.
Thankfully the single-file nature of the program and necessity of heavily restricting dependencies avoided most C++ unpleasantness; it also provided an excellent opportunity to get my feet wet with real hand-written lexing & parsing code.
It was spooky how easy it was.
I’d assumed lexing & parsing was this unbelievably difficult field, but it was strange how little logic it took to start correctly parsing some pretty complicated cases!
This is something I had read about before, and is kind of analogous to the experience of writing a recursive function: you don’t feel as though you’ve wrapped your head around it or handled everything (just the base case and general case), but it just… works?
After dispatching with parsing conjunction & disjunction lists I only had one more context-sensitive dragon to slay: proofs. TLA⁺ includes an entire language for writing formally-verified proofs that most people never encounter if they’re only writing specs for modelchecking. Proofs are structured hierarchically, with statements broken down into subproofs and those subproofs broken down into further subproofs, and so on, following the style laid out in Leslie Lamport’s paper How to Write a 21st Century Proof. This looks like:
THEOREM X
PROOF
<*> A
PROOF
<+> B
<1> QED
PROOF
<*> C
<3> D
<*> QED
<2> QED
<0> QED
Don’t be misled, most proofs aren’t this ugly - I am just trying to depict a good cross-section of syntax.
Proof step levels are denoted by a confusing mixture of explicit numbers (<3>) and contextually-relevant symbols (<*>, <+>).
Figuring out all these rules was quite a challenge and I eventually ended up with this somewhat-deranged state diagram for how the external scanner should modify its state in response to tokens as they appear:
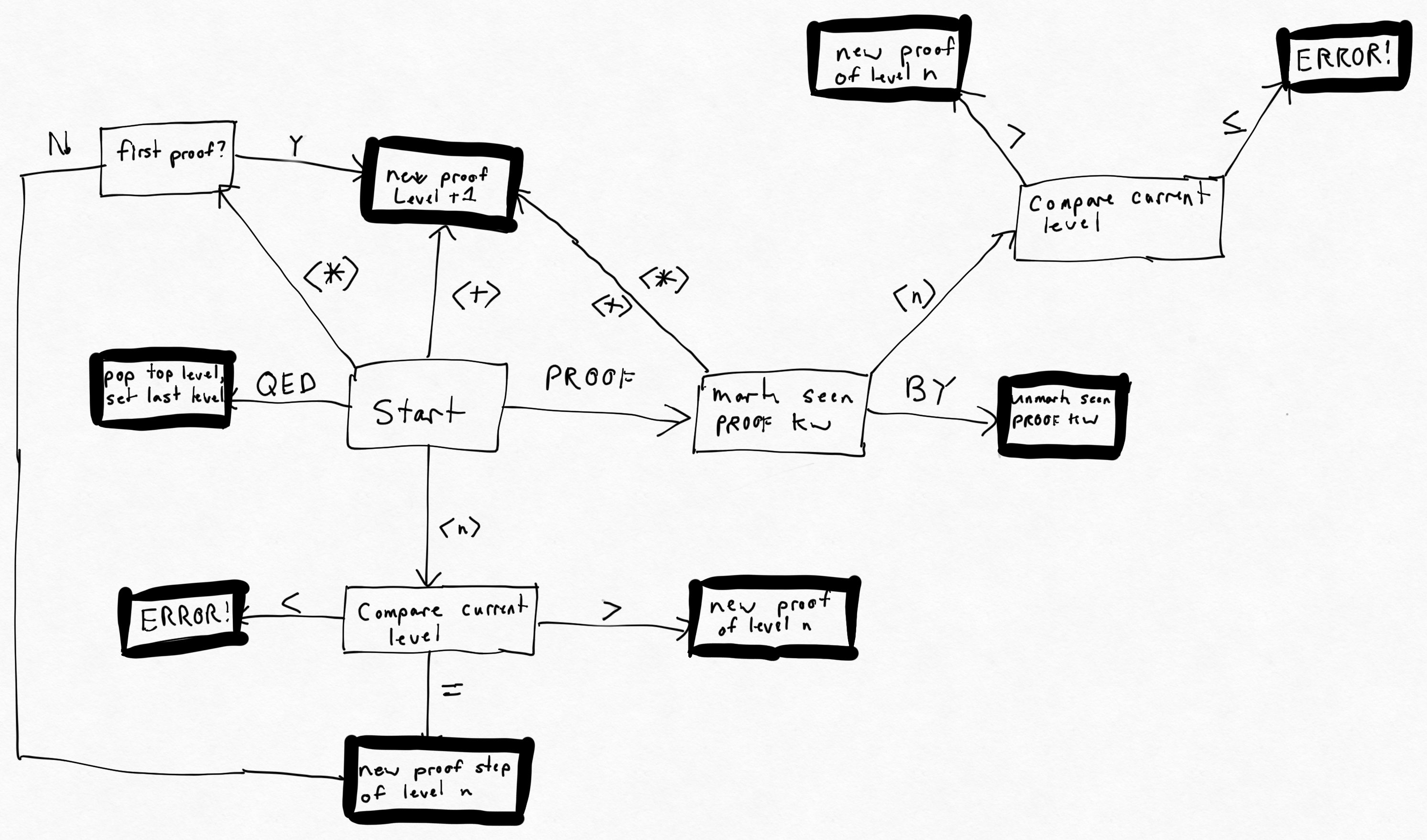 It was also tricky getting proofs to play nice with conjunction & disjunction lists.
It all worked out in the end though, and now you can do things like fold TLA⁺ proofs below a certain level in neovim!
Certainly a reasonable trade for an entire month of my life.
It was also tricky getting proofs to play nice with conjunction & disjunction lists.
It all worked out in the end though, and now you can do things like fold TLA⁺ proofs below a certain level in neovim!
Certainly a reasonable trade for an entire month of my life.
At that point I was essentially done; there were a hundred small fixes and refinements to make but the real work was finished. It was gratifying to finally ship a usable TLA⁺ tree-sitter grammar. Something people can use, something that did not exist in the world before and was only brought into being through a person’s labor. It was my first real free software project! After presenting the project at TLA⁺ conf 2021, I let it stabilize so it could evolve in response to user requirements. 2022 saw two impressive pieces of work by others: Vasiliy Morkovkin extended the grammar to parse PlusCal, a TLA⁺ variant for specs that are more sequential than event-driven. Then, William Schultz implemented a web-based TLA⁺ interpreter on top of the tree-sitter parse tree enabling you to explore the state graph by choosing which action to perform; this idea was discussed at the TLA⁺ conf so it was cool to see it implemented so quickly! One other notable integration was GitHub itself picking the grammar for syntax highlighting: now every TLA⁺ file (example) and code snippet on the site is highlighted with the grammar.
Becoming a free software developer
To me, becoming a free software developer was not accomplished when I began writing a free software project. I don’t mean this in the gatekeeping sense. I mean there was a transformation in worldview that occurred over time as I responded to incentives in the system. If I were to sum up the transformation, it would be this - at the start, I would look at a free software project driven by a handful of developers and think: this is their software. Eventually, I looked at that project and thought: this is our software. I can break this transformation down into five discrete steps of interaction with free software projects, all of which I moved through as I developed the grammar and interacted with dependencies:
- Writing internet comments complaining about bugs or missing features in a free software project.
- Reproducing a bug or spec’ing a feature, opening an issue in the project’s issue tracker, then waiting for them to fix it while occasionally asking for updates.
- Forking the project’s repo, writing the changes myself, opening a PR against the repo, then waiting for them to merge it while occasionally asking for updates.
- Creating my own release of the software from the fork containing my changes, so I or others can use it until the changes are upstreamed.
- Creating forks of other pieces of software that depend on the upstream project, updating their dependency to point to my first fork, then releasing the second fork so I or others can use it until the changes are upstreamed and the dependency updated.
I am not trying to create a moral hierarchy here. I have written my share of internet comments complaining about free software projects, even recently! You could say I’m still a bit half-baked. Perhaps we need to add an as-yet-unachieved sixth step:
- Apply perspective evolution of steps 1-5 to all free software projects, not just projects directly necessary to accomplish my own projects.
I am only responding to incentives: wanting software to function in a certain way, wanting that sooner rather than later, and having (or developing!) the technical know-how to make it do that. So why did these incentives not work their magic on me before? I’ve been a professional software engineer for about a decade now, and studied computer science in university for years prior to that. The answer is time and agency.
While working inside a large corporation I was trained to push issues to the owning team, with a transitory visit to that team’s PM who would do their best to bully me into making it my team’s problem - a mistake I made only once, before realizing the PM’s job was not to achieve a mutually-beneficial separation of labor but rather to scare away obligations (my PM friends were very entertained by this story of naivete - I had played the wrong language game). At work and in my personal life I almost exclusively used proprietary software. With proprietary software you are trapped in the role of simple consumer. If you want changes, you can usually only get to step 1 of the above interaction tiers - complaining online. If you’re anomalously lucky, the company developing the proprietary software might have a community suggestions site for you to make a half-assed attempt at step 2. And that’s where things died - I was trained to have no agency in my interactions with software. I read a nice post by Protesilaos Stavrou who phrased this in terms of autonomy: rule by one’s self, vs. heteronomy: rule by another. I readily translated this learned helplessness to free software, even though the reasons behind it were no longer present.
At the large corporation, my assigned work tasks fully consumed my time and, more importantly, my productive energy. Yet time is a funny thing - there’s a phrase heard in rock climbing and elsewhere, “slow is smooth and smooth is fast”. This was the enduring experience of working on this project. I was on sabbatical, with nobody to tell me what to do with my time & how to do it. Most days I felt like an old man wandering around, poking things with a stick. I would take the time to really read documentation, writing tiny prototypes to make sure I understood how things ticked. This was pleasant in itself. It would never have flown at the corporation, with its manager-led daily standup and demoralizing expectation that anything other than uniform incremental daily progress was an aberration to be corrected. I would not have received clearance to spend three weeks learning rust to implement a feature in a dependency. Development in a corporation is frenetic. You are only to learn how dependencies work at the shallowest level, to facilitate completion of work items in preparation for accepting further work items. These enduring gaps in understanding, the constant acquisition and then disposal of uninteresting surface-level knowledge, is to me a recipe for burnout. I need my learning to compound. But things certainly appear to move quickly! By contrast if we say my development pace on this sabbatical was glacial, the comparison is apt: slow, but inexorable and all-encompassing by way of advance. At the end of six months I had accomplished more than I ever had during any six-month period at a corporation, by a multiple. Is it possible to translate this style of development inside a corporation? I really don’t know. But I think it’s the development style necessary to thrive in free software. It looks slow. But it compounds, and becomes very fast. Fixing upstream issues isn’t a burden, it’s an accelerator.
I’m going to try to write fewer mean comments about free software projects on the internet. With my words I’m just disparaging myself. These projects offer something important to me that no proprietary software can ever match.
Conclusion
Veteran free software maintainers will note I’m still in the honeymoon period where each additional user of my projects brings happiness instead of piling on top of an already-crushing support burden. I also haven’t yet dealt with some contentious social situation forcing me to choose between suppressing my desires or starting & maintaining a fork of a dependency. I also haven’t even touched the topic of sustainable free software development, aka “how can you afford to spend time on this”. Currently my answer is by doing consulting contracts, earning enough to live comfortably-if-frugally while also devoting a substantial chunk of the year to free software development (and burnout recovery). So if you’re looking for someone to apply formal methods to your distributed system, among many other things, drop me a line at consulting@disjunctive.llc and hopefully I can keep this virtuous cycle turning!